ますます使えるようになったPhotoPrism
以前の記事でPhotoPrismを絶賛してから、地味に使い続けています。
GoogleフォトはもうサブのサブくらいのポジションになってしまってPhotoPrismがメイン環境として完全に定着しました。
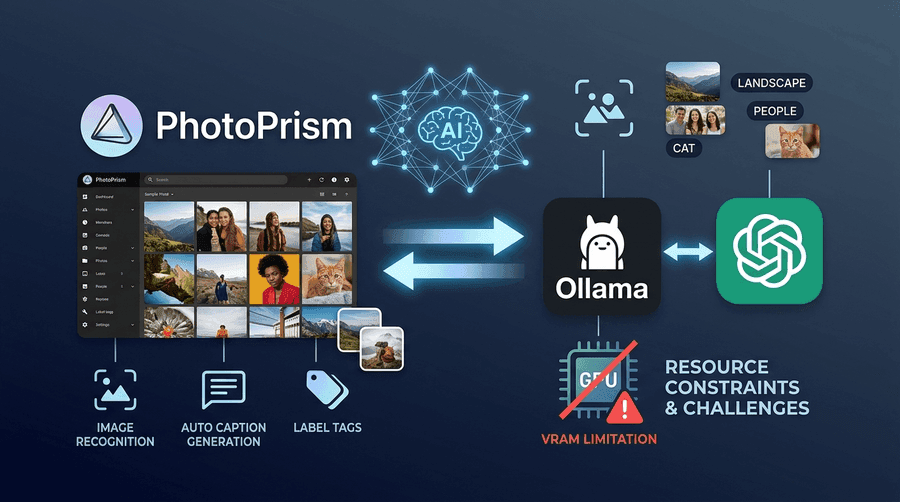
そんなPhotoPrismですが、ここ最近のアップデートで結構面白い機能が入ってきています。とくに2025年11月末の大型アップデートでOllamaやOpenAIと直接連携してキャプションやラベルを自動生成できるようになったのが個人的にはトピック。
試したので、その所感と、ついでに最近のアップデートまとめをサクッと備忘録的に書いておきます。
AIでキャプション・ラベル自動生成が来た
PhotoPrismはもともと内蔵のTensorFlowベースのモデルでラベル付け(タグ付け)をしてくれていたわけですが、2025年11月30日のアップデートで外部のVLM(Vision-Language Model)と連携してもっとリッチなキャプションやラベルを生成できるようになりました。
連携先として正式にサポートされたのが Ollama と OpenAI Responses API の2つ。Ollamaを使えばローカル完結、OpenAIを使えばクラウド側に投げる、という選択ができます。
ちなみに7月7日のリリースで先行して「Vision AIサービス経由でのOllamaサポート」が入っていたのですが、11月末のアップデートで本体に直接統合された形です。プロ版だけじゃなく無償版でも普通に使えます。
設定は vision.yml という設定ファイルにモデルとエンドポイントを書くだけ。compose.yaml のサンプルにも公式で ollama サービス例が追加されたので、Docker Composeでサクッと立てている人には導入のハードルが下がりました。
CopyModels:
- Type: caption
Model: gemma4:latest
Engine: ollama
Run: auto
Service:
Uri: http://ollama:11434/api/generate
こんな感じで書くだけ。Run を auto にしておけばインデックス後に自動的に走ってくれます。
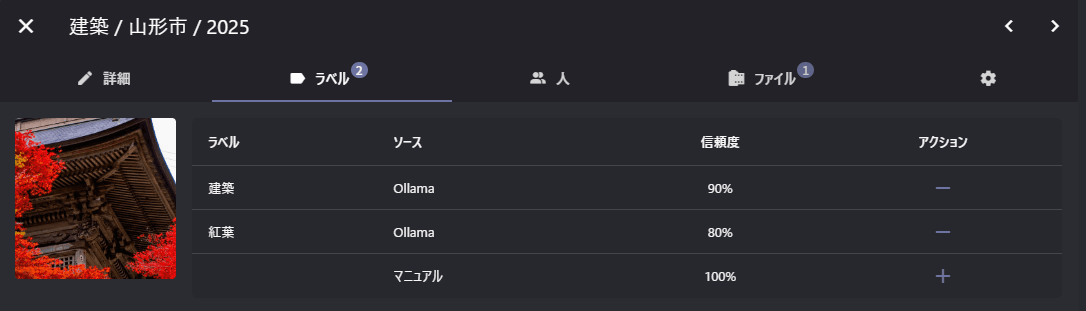
↓こんな感じでラベルやキャプションを自動で入れてくれるのでとても有用です。
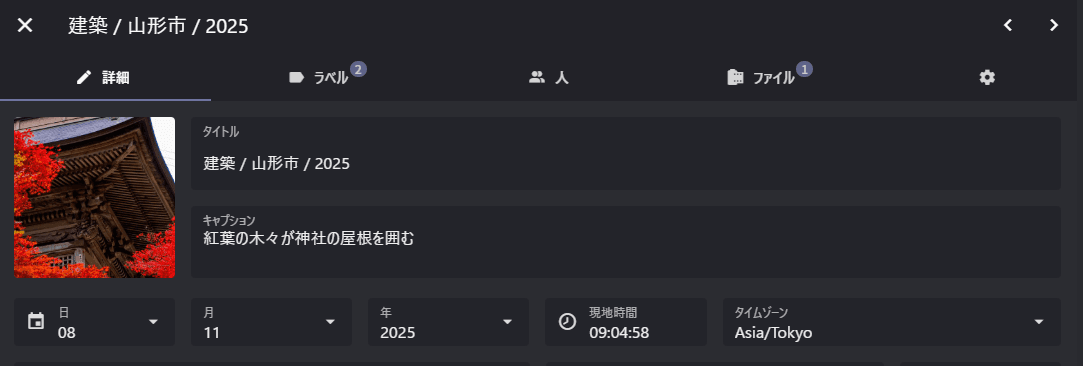
精度などは使用するモデルによって変わると思うのであまり参考にならないですが。。
自分のサーバーでOllamaを試した
「ローカル完結でAIキャプション、最高じゃん」と思ったので当然試しました。
公式が推奨しているのは Gemma 4 と Qwen3-VL の2つ。Gemma 4は軽くて出力が安定、Qwen3-VLは精度高めだけど少し重め、というキャラ分け。公式ドキュメントを見るとNVIDIA RTX 4060でラベル生成が約2秒(Gemma 4)〜23秒(Qwen3-VL)と書かれています。
問題は、PhotoPrismを動かしているうちのサーバーにはGPUが載っていないという点。
まずはサーバー側でCPUオンリーで gemma4:e2b(軽量版)を走らせてみたところ、動くは動くんですけど1枚あたり数十秒。
仮に1枚30秒として、5万枚処理しようとすると約17日。
常時CPUがブン回り、その間サーバーは熱を持ち、他のコンテナの動作にも影響が出る。これは現実的じゃない。
ちなみに自宅でサーバとして使用しているPCはこちらをUbuntuで運用しています。

「じゃあメインPCでやればいいじゃん」ということで、RTX 3060 Tiを積んでいるメインPCにOllamaを入れて、PhotoPrismから接続して試してみました。
Ollamaは OLLAMA_HOST=0.0.0.0 で起動すれば普通にLAN経由で叩けるので、サーバー側のPhotoPrismから別マシンのOllamaを参照する構成自体は問題なく組めます。
ところがここで詰まったのが VRAM 8GB問題。
Gemma 4の e4b(標準)もQwen3-VLの 4b-instruct も、量子化されてるとはいえモデルとKVキャッシュをVRAMに載せるとギリギリ収まらない、もしくは画像入力分のコンテキストを足すと溢れるといった挙動になります。
Ollamaは賢いのでVRAMに乗りきらない分は自動でCPU側にオフロードしてくれるんですが、結局GPUとCPUのハイブリッド処理になって思ったほど速度が出ない。
実測でラベル生成が1枚15〜25秒くらい。これだとサーバーCPUオンリーよりは速いものの、結局GPUの恩恵を十分に受けられていないという中途半端な状態でした。
gemma4:e2b まで落とせばVRAMには収まるんですが、今度は精度が物足りない。
あと、メインPCを24時間動かしっぱなしにする運用は電気代的にも環境的にも厳しい。
サーバーに常駐させる方向じゃないと運用としてイマイチ、というのもあって、結局Ollamaでの常用は諦めました。
OpenAI APIに投げるという選択肢もあるんですが、プライベートな写真をクラウドのLLMに送るのはちょっと心理的に抵抗があるので今のところはPhotoPrism内蔵のTensorFlowモデルで満足することにしています。
内蔵モデルでも十分検索には使えるレベルのラベル付けはしてくれますし。
現実的な解としては、VRAM 12GB以上のGPU(RTX 3060 12GB版とかRTX 4070以降)を別筐体で「AI推論専用ノード」として組むとか、Mac miniのApple Silicon系を推論サーバーにするとか、そのへんになりそう。
ついでに最近の主要アップデートまとめ
Ollama統合だけが目立っていますが、それ以外にも結構入っているので、前回記事以降の主だった変更をリリースノートまとめ的に書いておきます。
2026年3月(260305)
Ollama設定が OLLAMA_BASE_URL と OLLAMA_API_KEY という環境変数で書けるようになりました。vision.yml を直接いじらなくてもいいので楽。あと、reasoning系モデル(思考過程を出力するタイプ)使用時のキャプション生成のフォールバック処理も改善されています。
2025年11月30日(251130)— 大型アップデート
個人的に一番嬉しいのは Batch Edit(一括編集ダイアログ) がついに実装されたこと。複数の写真のメタデータをまとめて書き換えられるようになりました。これずっと欲しかったやつ。
それと、顔認識エンジンが新しいCNNベースのものに刷新されてマッチング精度が向上。既存のデータベースに対して反映させたい場合は photoprism faces audit --fix → photoprism faces index を実行する必要があります(完全に作り直したいなら faces reset -f のあと faces index、ただし再アサインが必要)。
その他、人物のカバー画像変更、複数アルバム同時追加、PHOTOPRISM_DISABLE_TENSORFLOW の非推奨化(複数AIエンジン対応のため)など。
2025年7月7日(250707)
地図上で写真の座標を後から修正できる「Adjust Location」ダイアログ追加。Exif情報がない写真や、間違ったGPS情報を持ってる写真の修正に便利。あとアルバムツールバーからの削除アクション、地名表示言語の設定なども追加。
2025年4月25日(250425)— 大型アップデート
TensorFlowが1.15.2から2.18.0にアップグレード。これに伴いARMv7(32bitのRaspberry Pi)は本流から外れて別ブランチ管理に。Pi 4以降の64bit環境なら問題なし。
UX面ではフロントエンドのバンドルサイズが54%減って体感的にも速くなりました。フルスクリーンビューワーに折りたたみ式のメタデータサイドバーが追加されたのも地味に便利。ZIPでまとめて写真をアップロードできるようにもなりました。
2025年3月21日(250321) PDFファイル対応。
これ意外と便利で、書類のスキャン画像をPDFで保管してる場合とかに地味に効きます。あとサイドバーのディスク使用量表示、カードビューの表示メタデータ設定など。
とりとめのないまとめ
AIキャプション機能は「環境さえあれば最高」のやつですが、私のように非力なホームサーバー運用組にとっては、まだ手の届きにくい機能でした。
とはいえ、PhotoPrism本体としては Batch Edit や顔認識改善、PDF対応など実用度の高い機能がどんどん入ってきていて、写真管理ツールとしての完成度がさらに上がっている印象です。
PhotoPrismはOSSなのに開発ペースが落ちないのが本当にすごい。compose.yaml の image: を photoprism/photoprism:latest のままにしておけば docker compose pull && docker compose up -d で最新版に追従できるので、定期的に更新するのがおすすめです。
コメント
コメントを読み込み中...